Note
Click here to download the full example code
OpenMP and CUDA#
Accelerating pygpc by using different computing backends#
This tutorial shows how to accelerate pygpc by choosing different computing backends. At the moment, the following backends are available:
Implementation in Python: pygpc names this backend python
Implementation in C++: pygpc names this backend cpu
Implementation in C++ and OpenMP: pygpc names this backend omp
Implementation in CUDA-C++: pygpc names this backend cuda, an Nvidia GPU is required
Installation of the CUDA backend#
Pygpc also provides a CUDA-backend to speed up some computations. To use the backend you need to build it manually. This requires the CUDA-toolkit and CMake. CMake can be installd via the pip command. Simply run the following command in your terminal:
pip install cmake
For the installation of the CUDA-toolkit please refer to: https://docs.nvidia.com/cuda/cuda-quick-start-guide/index.html. If CMake and the CUDA-toolkit are installed on your machine you can build the extension with:
python build_pygpc_extensions_cuda.py
Troubleshooting for OSX:
On a mac you need GCC to install pygpc. If you are using the brew package manager you can simply run:
brew install gcc libomp
Then install pygpc with:
CC=gcc-9 CXX=g++-9 python setup.py install
Troubleshooting for Windows:
On windows you might need a compiler to install pygpc. To install the Visual C++ Build Tools, please refer to: http://go.microsoft.com/fwlink/?LinkId=691126&fixForIE=.exe.
Setting up benchmark parameters#
We define the number of samples, the dimensionality of the parameter space and the maximum number of basis functions. This will determine the size of the gPC matrix and therefore the compute time.
# Windows users have to encapsulate the code into a main function to avoid multiprocessing errors.
# def main():
n_dim = 4 # number of random variables (defines total number of basis functions)
n_basis_order = 8 # polynomial approximation order (defines total number of basis functions with n_dim)
n_samples = 100000 # number of random samples (number of rows in gPC matrix))
n_qoi = 100 # number of QOIs (number of columns in gPC coefficient matrix)
n_iterations = 3 # number repeated benchmark runs
Setting up the gPC and the grid of sampling points#
import pygpc
import numpy as np
from collections import OrderedDict
# define model
model = pygpc.testfunctions.DiscontinuousRidgeManufactureDecay()
# define parameters
parameters = OrderedDict()
for i_dim in range(n_dim):
parameters["x"+str(i_dim)] = pygpc.Beta(pdf_shape=[1, 1], pdf_limits=[1.2, 2])
# define problem
problem = pygpc.Problem(model, parameters)
# define grid
options = dict()
grid = pygpc.Random(parameters_random=problem.parameters_random,
n_grid=n_samples,
options={"n_grid": n_samples, "seed": 1})
# define gPC
gpc = pygpc.Reg(problem=problem,
order=[n_basis_order] * n_dim,
order_max=n_basis_order,
order_max_norm=1,
interaction_order=n_dim,
interaction_order_current=n_dim,
options=options)
gpc.grid = grid
# get number of basis functions
n_basis = pygpc.get_num_coeffs_sparse([n_basis_order] * n_dim, n_basis_order, n_dim, n_dim, n_dim, 1)
# create coefficient matrix
coeffs = np.ones((len(gpc.basis.b), n_qoi))
Running the benchmark#
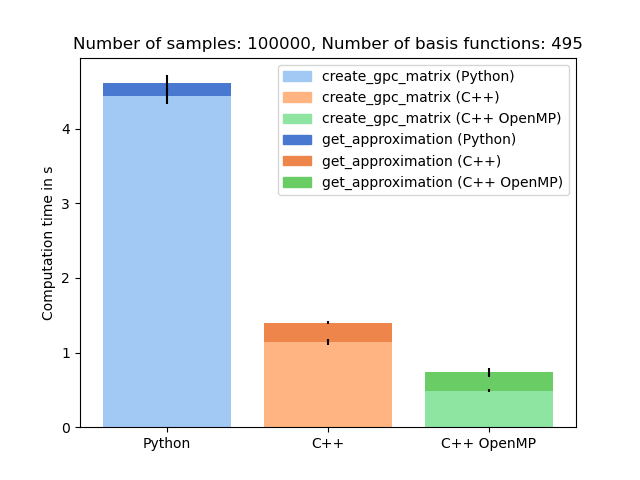
Per default the omp-backend is set. Let’s try them all and see how the performance changes. If you have installed the CUDA backend you can add “cuda” to the list of backends. It is the fastest one and outperforms all other backends.
import time
backends = ["python", "cpu", "omp"] # "cuda"
labels = ["Python", "C++", "C++ OpenMP"] # "CUDA"
time_create_gpc_matrix = OrderedDict()
time_get_approximation = OrderedDict()
for b in backends:
time_create_gpc_matrix[b] = []
time_get_approximation[b] = []
# warmup to wake gpu up from idle
if "cuda" in backends:
for _ in range(10):
gpc.backend = "cuda"
gpc.create_gpc_matrix(b=gpc.basis.b, x=gpc.grid.coords_norm)
# benchmark
for _ in range(n_iterations):
# python backend
for b in backends:
gpc.backend = b
# benchmark create_gpc_matrix
start = time.time()
gpc.create_gpc_matrix(b=gpc.basis.b, x=gpc.grid.coords_norm)
stop = time.time()
time_create_gpc_matrix[b].append(stop - start)
# benchmark get_approximation
start = time.time()
gpc.get_approximation(coeffs, x=gpc.grid.coords_norm)
stop = time.time()
time_get_approximation[b].append(stop - start)
Performance comparison between the backends#
import seaborn as sns
from matplotlib import pyplot as plt
from matplotlib import patches as mpatches
# plot results
patches_muted = []
patches_pastel = []
for ind, b in enumerate(backends):
plt.bar(ind, np.mean(time_get_approximation[b]),
yerr=np.std(time_get_approximation[b]),
color=sns.color_palette("muted", len(backends))[ind])
plt.bar(ind, np.mean(time_create_gpc_matrix[b]),
yerr=np.std(time_create_gpc_matrix[b]),
color=sns.color_palette("pastel", len(backends))[ind])
patches_muted.append(mpatches.Patch(
color=sns.color_palette("muted", len(backends))[ind],
label="get_approximation (" + labels[ind] + ")"))
patches_pastel.append(mpatches.Patch(
color=sns.color_palette("pastel", len(backends))[ind],
label="create_gpc_matrix (" + labels[ind] + ")"))
plt.ylabel("Computation time in s")
plt.xticks(range(len(labels)), labels)
plt.title("Number of samples: {}, Number of basis functions: {}".format(n_samples, n_basis))
_ = plt.legend(handles=patches_pastel + patches_muted)
# On Windows subprocesses will import (i.e. execute) the main module at start.
# You need to insert an if __name__ == '__main__': guard in the main module to avoid
# creating subprocesses recursively.
#
# if __name__ == '__main__':
# main()
Total running time of the script: ( 0 minutes 42.891 seconds)